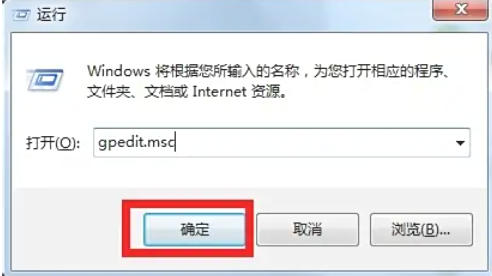
在人工智能技术快速迭代的当下如何将尖端AI能力转化为个人生产力工具?小编以DeepSeek模型为例,系统梳理本地部署全流程,助您构建专属智能工作站。通过两种主流部署方案对比解析,不同硬件配置下的性能表现差异,以及常见问题的应对策略,为技术爱好者打开AI本地化应用新视界。
一、构建AI实验室的硬件基石
工欲善其事必先利其器,部署前的硬件规划直接影响模型运行效能。我们建议根据应用场景分级配置:
1. 入门级方案:16GB内存搭配RTX 406显卡,可流畅运行7B参数模型,满足日常文本处理需求
2. 创作增强型:32GB内存配合RTX 409显卡,支持更大参数模型的推理运算,提升内容生成质量
3. 科研工作站:64GB内存+RTX 509D(32GB显存),构建多模态模型训练环境,解锁完整AI开发潜能
二、软件环境搭建要点
1. 系统选择:优先采用Linux系统(Ubuntu 20.04 LTS推荐),Windows用户需确保系统版本为10/11专业版
2. 开发环境:Python 3.8+版本配合PyTorch 1.12框架,建议安装Anaconda管理依赖包
3. 加速组件:CUDA 11.7与cuDNN 8.5组合,最大化GPU运算效率
三、主流部署方案详解
方案A:Ollama框架快速部署
1. 框架安装:访问Ollama官网获取最新安装包,Windows用户建议默认安装路径
2. 环境验证:终端执行`ollama-v`查看版本信息,确认服务进程正常启动
3. 模型集成:通过`ollama pull deepseek`获取指定版本模型,支持7B/13B等参数规格
4. 交互优化:配置Chatbox客户端(v2.4.1+),实现可视化对话界面
方案B:GitHub源码深度部署
1. 代码获取:执行`git clone https://github.com/deepseek-ai/core.git`克隆主仓库
2. 环境隔离:创建Python虚拟环境避免依赖冲突
python -m venv ds_env
source ds_env/bin/activate # Linux
ds_envScriptsactivate.bat # Windows3. 依赖安装:通过`pip install -r requirements.txt`安装指定版本组件包
4. 模型加载:运行`python download_model.py --model_version=v2.1`获取最新预训练模型

四、模型调优与问题排查
1. 性能加速:在config.json中设置`"use_cuda":true`启用GPU加速,需匹配CUDA 11.x环境
2. 内存优化:调整`max_batch_size`参数平衡显存占用与处理速度
3. 常见异常处理:
- 依赖冲突:使用`pip check`验证包兼容性
- 模型加载失败:检查sha256校验值,必要时手动下载模型文件
- AMD显卡适配:安装ROCm 5.6驱动套件,配合LM Studio优化计算流程

五、进阶应用场景拓展
1. api服务部署:通过`uvicorn app:api --port 800`启动RESTful接口服务
2. 多模型协同:配置Model Ensemble实现7B与13B模型的联合推理
3. 自定义训练:加载LoRA模块进行领域适配微调,需预留至少24GB显存

当完成全部部署步骤后,建议运行基准测试脚本评估系统效能。通过调整量化精度(FP16/INT8)可在精度损失与计算速度间取得平衡。定期更新模型版本可获取最新改进的对话能力和知识库扩展。